Spatio-Temporal Filter Adaptive Network for Video Deblurring
Shangchen Zhou*, Jiawei Zhang*, Jinshan Pan, Haozhe Xie, Wangmeng Zuo, Jimmy Ren
Abstract
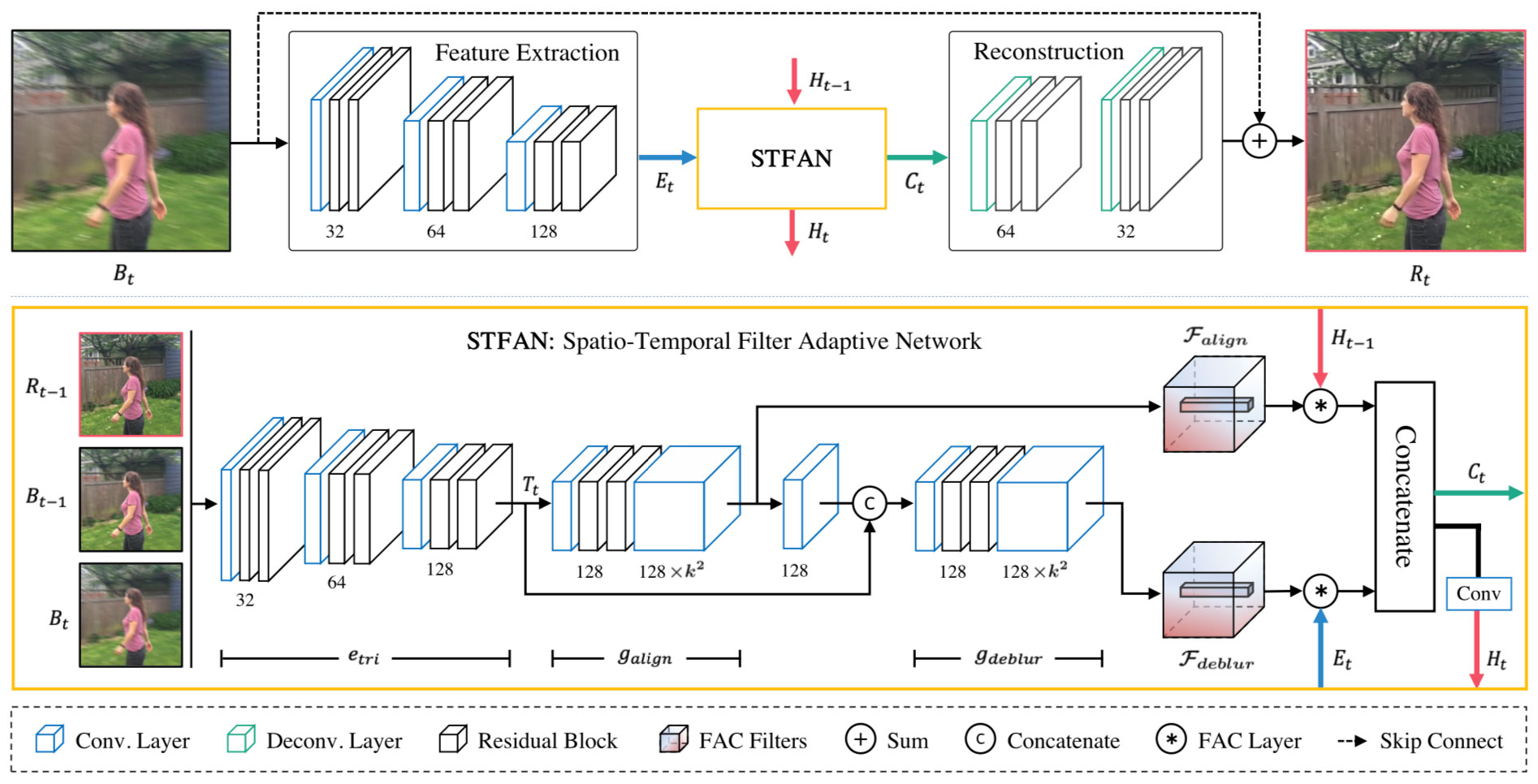
Video deblurring is a challenging task due to the spatially variant blur caused by camera shake, object motions, and depth variations, etc. Existing methods usually estimate optical flow in the blurry video to align consecutive frames or approximate blur kernels. However, they tend to generate artifacts or cannot effectively remove blur when the estimated optical flow is not accurate. To overcome the limitation of separate optical flow estimation, we propose a Spatio-Temporal Filter Adaptive Network (STFAN) for the alignment and deblurring in a unified framework. The proposed STFAN takes both blurry and restored images of the previous frame as well as blurry image of the current frame as input, and dynamically generates the spatially adaptive filters for the alignment and deblurring. We then propose a new Filter Adaptive Convolutional (FAC) layers to align the deblurred features of the previous frame with the current frame and remove the spatially variant blur from the features of the current frame. Finally, we develop a reconstruction network which takes the fusion of two transformed features to restore the clear frames. Both quantitative and qualitative evaluation results on the benchmark datasets and real-world videos demonstrate that the proposed algorithm performs favorably against state-of-the-art methods in terms of accuracy, speed and model size.

Citation
@inproceedings{zhou2019stfan,
title={Spatio-Temporal Filter Adaptive Network for Video Deblurring},
author={Zhou, Shangchen and Zhang, Jiawei and Pan, Jinshan and Xie, Haozhe and Zuo, Wangmeng and Ren, Jimmy},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year={2019}
}
Citation
@inproceedings{zhou2019stfan,
title={Spatio-Temporal Filter Adaptive Network for Video Deblurring},
author={Zhou, Shangchen and Zhang, Jiawei and Pan, Jinshan and Xie, Haozhe and Zuo, Wangmeng and Ren, Jimmy},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year={2019}
}
Filter Adaptive Convolutional Layer
The proposed filter adaptive convolutional (FAC) layer applies generated pixel variant filters to the features, In theory, the element-wise adaptive filters is five-dimensional ($h \times w \times c \times k \times k$). In practice, the dimension of the generated filter $\mathcal{F}$ is $h\times w\times ck^2$ and we reshape it into the five-dimensional filter. For each position $(x, y, c_i)$ of input feature $Q\in \mathcal{R}^{h\times w\times c}$, a specific local filter $\mathcal{F}_{x, y, c_i}\in \mathcal{R}^{k\times k}$ (reshape from $1\times 1\times k^2$) is applied to the region centered around $Q_{x, y, c_i}$.
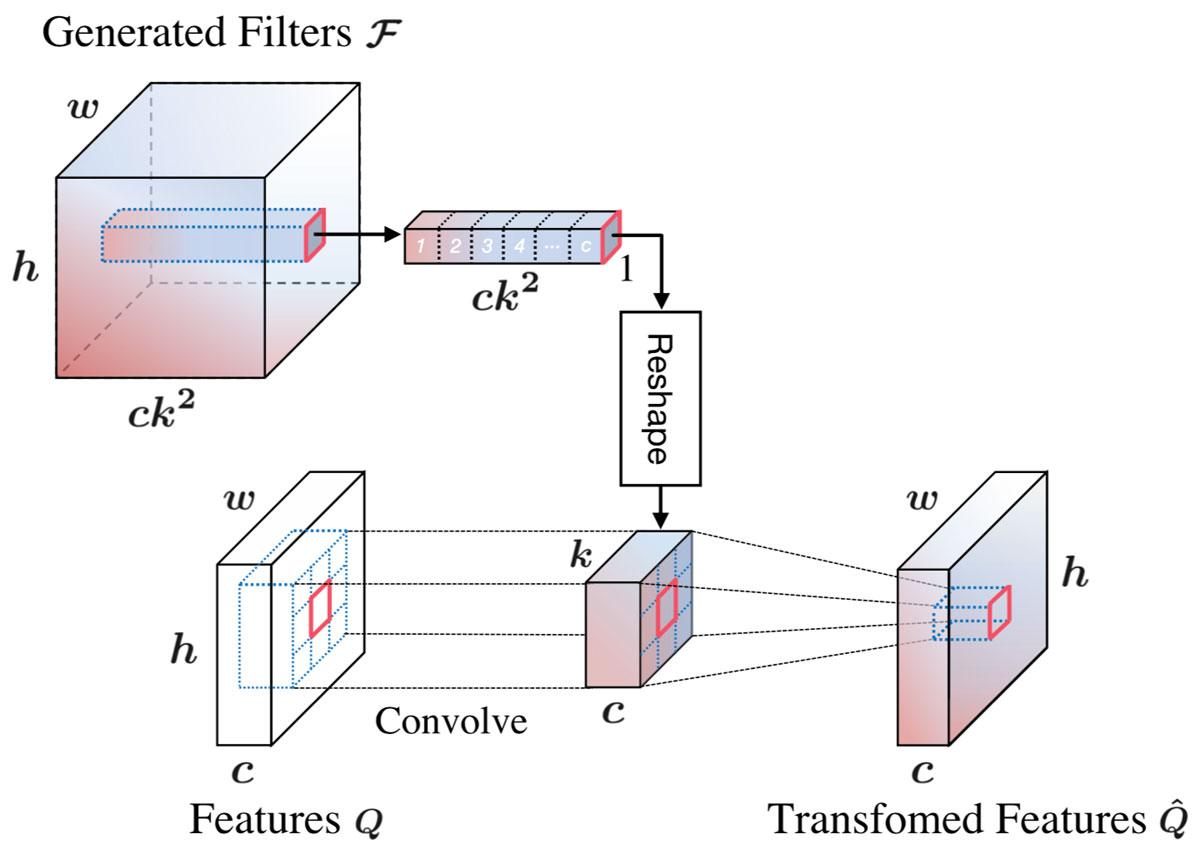
➤ The forward pass of the proposed Filter Adaptive Convolutional (FAC) Layer is as follows:
$$\hat{Q}(x, y, c_i) = \mathcal{F}_{x, y, c_i} \ast Q_{x, y, c_i} \nonumber = \sum_{n=-r}^{r} \sum_{m=-r}^{r} \mathcal{F}(x, y, k^2c_i+kn+m) \times Q(x-n, y-m, c_i)$$
➤ The backward pass can be presented as:
$$\Delta{Q}(x, y, c_i) = \sum_{n=-r}^{r} \sum_{m=-r}^{r} \mathcal{F}(x+n, y+m, k^2c_i+kn+m) \times \Delta{\hat{Q}}(x+n, y+m, c_i)$$
$$\Delta{\mathcal{F}}(x, y, k^2c_i+kn+m) = Q(x-n, y-m, c_i) \times \Delta{\hat{Q}}(x, y, c_i)$$
in which $r=\frac{k-1}{2}$, $\mathcal{F}$ is the generated filter, $Q$ and $\hat{Q}$ denote the input features and transformed features, respectively.
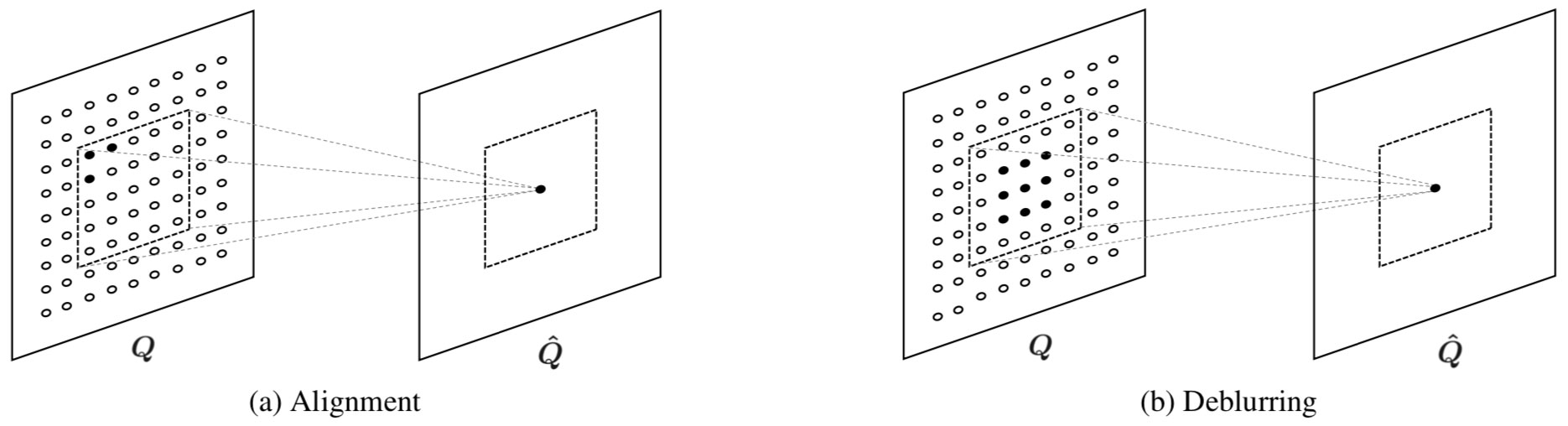
Illustration of Alignment and Deblurring Processes by FAC layer
The frame alignment and deblurring are both spatially variant tasks. Using the proposed FAC layer, we consider these two processes as two filter adaptive convolution in feature domain. The convolution operation can transform the pixels of features, which can be used for frames alignment (a) and deblurring (b) using estimated corresponding filters.
Experimental Results
Quantitative evaluation
Quantitative evaluation on the video deblurring dataset [4], in terms of PSNR, SSIM (averaged over all frames), running time (sec) and parameter numbers.
| Method | Tao et al. [1] | Kim and Lee [2] | Kim et al. [3] | Su et al. [4] | Ours |
|---|---|---|---|---|---|
| #Frames | 1 | 3 | 5 | 5 | 2 |
| PSNR | 29.97 | 27.01 | 29.95 | 30.05 | 31.24 |
| SSIM | 0.919 | 0.861 | 0.911 | 0.920 | 0.934 |
| Time (sec) | 2.52 | 880 | 0.13 | 6.88 | 0.15 |
| #Params (M) | 8.06 | - | 0.92 | 16.67 | 5.37 |
Results on testing dataset


Results on real blurry video

Contact
If you have any question, please contact Shangchen Zhou at shangchenzhou@gmail.com.
References
[1] X. Tao, H. Gao, X. Shen, J. Wang, and J. Jia. Scale-recurrent network for deep image deblurring. In CVPR, 2018.
[2] T. Hyun Kim and K. Mu Lee. Generalized video deblurring for dynamic scenes. In CVPR, 2015.
[3] T. Hyun Kim, K. Mu Lee, B. Scholkopf, and M. Hirsch. Online video deblurring via dynamic temporal blending network. In CVPR, 2017.
[4] S. Su, M. Delbracio, J. Wang, G. Sapiro, W. Heidrich, and O. Wang. Deep video deblurring for hand-held cameras. In CVPR, 2017.