Abstract
Text-based diffusion models have exhibited remarkable success in generation and editing, showing great promise for enhancing visual content with their generative prior. However, applying these models to video super-resolution remains challenging due to the high demands for output fidelity and temporal consistency, which is complicated by the inherent randomness in diffusion models. Our study introduces Upscale-A-Video, a text-guided latent diffusion framework for video upscaling. This framework ensures temporal coherence through two key mechanisms: locally, it integrates temporal layers into U-Net and VAE-Decoder, maintaining consistency in short sequences; globally, without training, a flow-guided recurrent latent propagation module is introduced to enhance overall video stability by propagating and fusing latent across the entire sequences. Thanks to the diffusion paradigm, our model also offers greater flexibility by allowing text prompts to guide texture creation and adjustable noise levels to balance restoration and generation, enabling a trade-off between fidelity and quality. Extensive experiments show that Upscale-A-Video surpasses existing methods in both synthetic and real-world benchmarks, as well as in AI-generated videos, showcasing impressive visual realism and temporal consistency.
Method
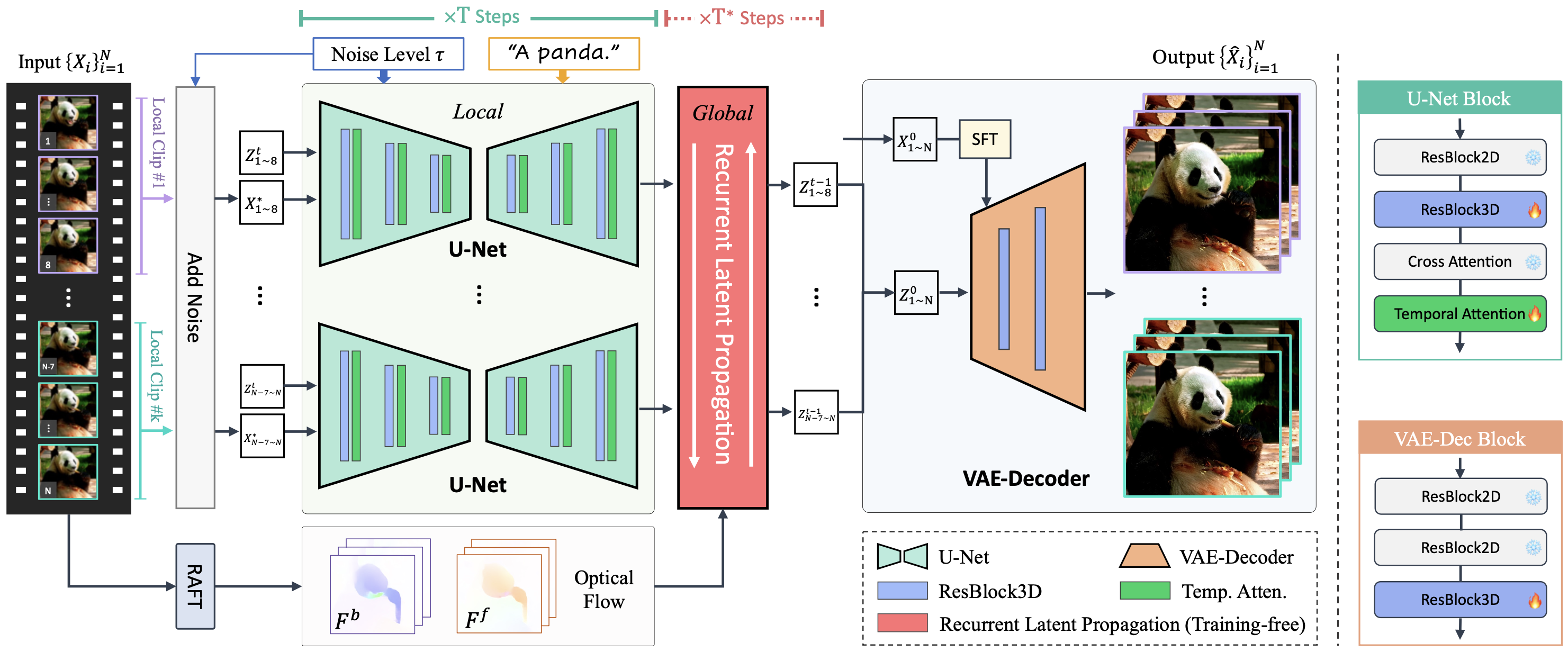
Upscale-A-Video processes long videos using both local and global strategies to maintain temporal coherence. It divides the video into segments and processes them using a U-Net with temporal layers for intra-segment consistency. During user-specified diffusion steps for global refinement, a recurrent latent propagation module is used to enhance inter-segment consistency. Finally, a finetuned VAE-Decoder reduces remaining flickering artifacts for low-level consistency.
Upscale-A-Video Demo
BibTeX
@InProceedings{zhou2024upscaleavideo,
title = {{Upscale-A-Video}: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution},
author = {Zhou, Shangchen and Yang, Peiqing and Wang, Jianyi and Luo, Yihang and Loy, Chen Change},
booktitle = {CVPR},
year = {2024}
}